Since February 2014 I’ve been working on the Content Discovery Team here at 7digital, we are responsible for every endpoint listed under Catalogue API here - http://developer.7digital.com/resources/api-docs/catalogue-api – and probably a few more. This is a mix of discovery endpoints and core catalogue endpoints often split by artist, albums (releases) and tracks. The discovery side of it consists of searching, recommendations, charts, genres, new and popular tracks and albums. The core catalogue endpoints are requests to the API for an album, tracks on an album, an artist, an artist’s releases or just track information using a 7digital unique identifier (referred to as releaseId, trackId and artistId).
Going back to early February the team, three developers, a QA and product manager, had inherited a maintenance nightmare. We owned around 20 endpoints across 4 applications all of which do vaguely similar things retrieving artist, release or track information. Except we were using two large out-of-sync data stores, a SQL Server database and a Solr data store. Solr essentially containing a denormalised version of what you would find in SQL.
Over the years there had been a push to use Solr as the single point of truth and there had been much investment to move all endpoints over to use it instead of SQL (a reasonable idea at the time). This meant we were using Solr for both text searching and Id lookups on most of the Catalogue endpoints but using SQL on a number of others. Furthermore we had to index all possible information relating to a track or release in Solr, much of which is territory specific. As an example; the price for an album is territory specific because it will be different in the UK to the US, as will the streaming and download release dates. In order to represent this data in a denormalised form in Solr, the solution was to duplicate every track and release across every territory it was available in. This was a particular problem for the track index. Given we have approximately 27 million tracks in our catalogue and content in 30 odd territories, this quickly led to a massive and expensive index of tracks which was pushing 660 GB in size and contained 700 million documents.
Due to the size of the index and the amount of data the ~/track/search endpoint performed horribly averaging 5 second response times. More pressing was the amount of unplanned and support-type work the team were performing in order to maintain the track index. This would vary from restarting live web servers to performing manual data updates to inactivate a track, which should no longer be available on the API. The latter was common because we couldn’t perform a full re-index as it would take up to FIVE DAYS and usually failed, so we built a complex indexing application which would only send to Solr those tracks which had changed. Unfortunately this workaround was built upon an existing process which was used to identify changes in the catalogue. This consisted of tons of triggers and scheduled jobs in SQL Server where it wasn’t uncommon to see nested views, temporary tables and layers of stored procedures. None of it was tested and all of it was impossible to follow and reason about.
Eventually a new feature came along which would have required many changes and additions at each step of this convoluted process. This gave us the business case required to begin simplifying our architecture. We recognised that we needed Solr for searching because this is exactly what it’s good at, but we saw no benefit in using it for Id lookups, particularly when we could be closer to the source data and have good performance using SQL Server. We wanted to shrink the size of the track index and so we needed to tackle a number of problems. We needed to remove territory specific data from the index so we could stop duplicating each track across 30 territories. We also needed to replace any unnecessary dependencies where possible and reduce the number of indexed fields to only those which should be searchable.
To do any of this we needed to source much of the data stored in Solr from somewhere else. We recognised early on that endpoints such as ~/track/search and ~/track/chart where just a list of tracks and a full track resource could be retrieved from another public endpoint; ~/track/details. With this in mind we set about improving a number of core catalogue endpoints (including ~/track/details) reducing response times dramatically, improving the code base and bringing the monitoring of these endpoints up to scratch with everything else. The ~/track/search endpoint could then look something like this:
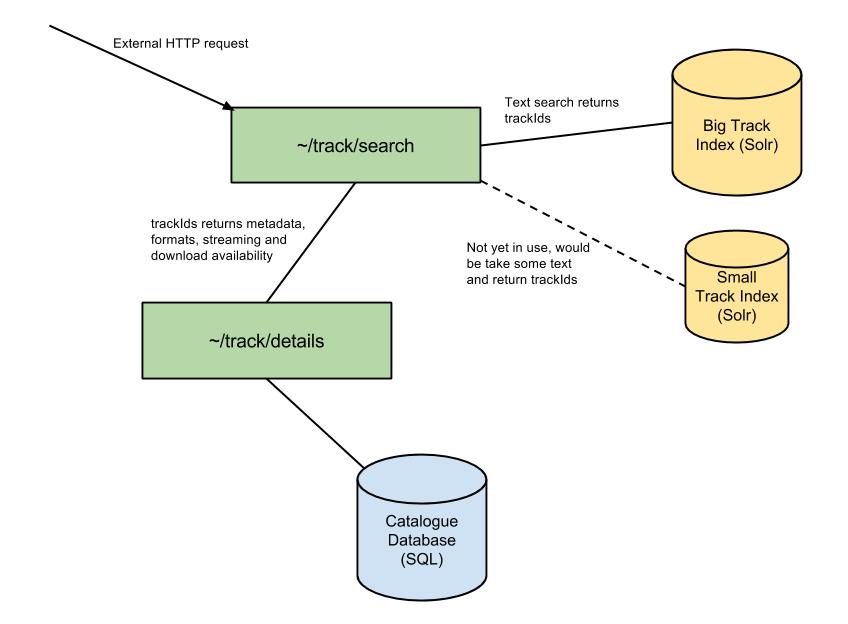
It remained on the old track index for a while but was only touching a few of the fields. Taking this incremental step, which had a small negative impact on performance, meant we could bring a new smaller index up and switch over to it with minimal disruption. We managed this risk further by using canary deploys too, rolling out searches on the new index to a few servers until we were satisfied enough to do a full deployment. The new track index weighed in at just over 6GB and response times are averaging 500ms, a dramatic improvement.
We can now do a full re-index of tracks within an hour, we do this twice a day. This allows us to experiment more freely using features of Solr and Lucene without being held back by technical debt. Now we make changes daily, which allows us to test out any assumptions. This is particularly valuable when working on something as complex and subjective as text search.
Crucially with the old track index gone unplanned work tailed off and we started delivering business value. Most recently adding auto-complete style searching to all three search endpoints and resolving some long standing problems with matching on artist names like P!nk and Ke$ha.
We’ve also taken all the release endpoints in a similar architectural direction, which will eventually mean we can iterate quickly on improving ~/release/search too. Technically we now have only one integration point with the catalogue database for releases and tracks, within ~/release/details and ~/track/details. Now that many of our APIs consume these endpoints we’ve improved consistency between them and we no longer have many tentacles going direct to the database, which will allow us to move a lot quicker and make improvements across the catalogue when needed.
In conclusion, we benefited from a number of key concepts: we simplified and refactored when working through each of these technical changes, removing a lot of unnecessary complexity. For example, approaching clients about removing rarely used optional parameters and in time removing them.
We tackled causes of unplanned work, often eliminating any immediate burden with small fixes and workarounds so we could focus more of the team’s energy on the wider problem. Similarly, we elevated these issues, making them visible to the rest of the business. This helped justify our business case for tackling the wider problem.
We automated the Solr infrastructure, this hasn’t been mentioned much as it’s still evolving, but we’re now able to push through configuration changes to production several times a day. This a world away from where we were and came about through a combination of configuration management (CFEngine), TDD (Test Kitchen, Vagrant), a few custom scripts to automate Solr core reloads and reducing the size of the track index.
Finally, we benefited most from lots of collaboration and communication inside and outside of the team, discussing the technical and architectural direction at length. We even started organising weekly discussions just to run through the architecture we were heading towards, any tweaks we could make or any problems we would encounter along the way. This architecture is continuing to evolve but it’s already paying off, with the team beginning to prove that we can deliver changes quickly to the 7digital catalogue.
For a more detailed and technical view on what we did and how we did it, check out Michael Okarimia’s posts: part one and part two.